
understand
可视化&开销分析
整个 PPT 的主题就是 understand - 可视化&开销分析: 先试用,再看它能不能把隐藏调用逻辑和瓶颈暴露出来, 重点不是“看懂代码”,而是把重要代码和执行归因挑出来。
试跑结论先说
它不是只会“读 README”。对这种典型电商 starter,它能稳定识别出前台页面、登录流、支付/结算、国际化、表单与表格、数据库 schema、middleware 保护路由。
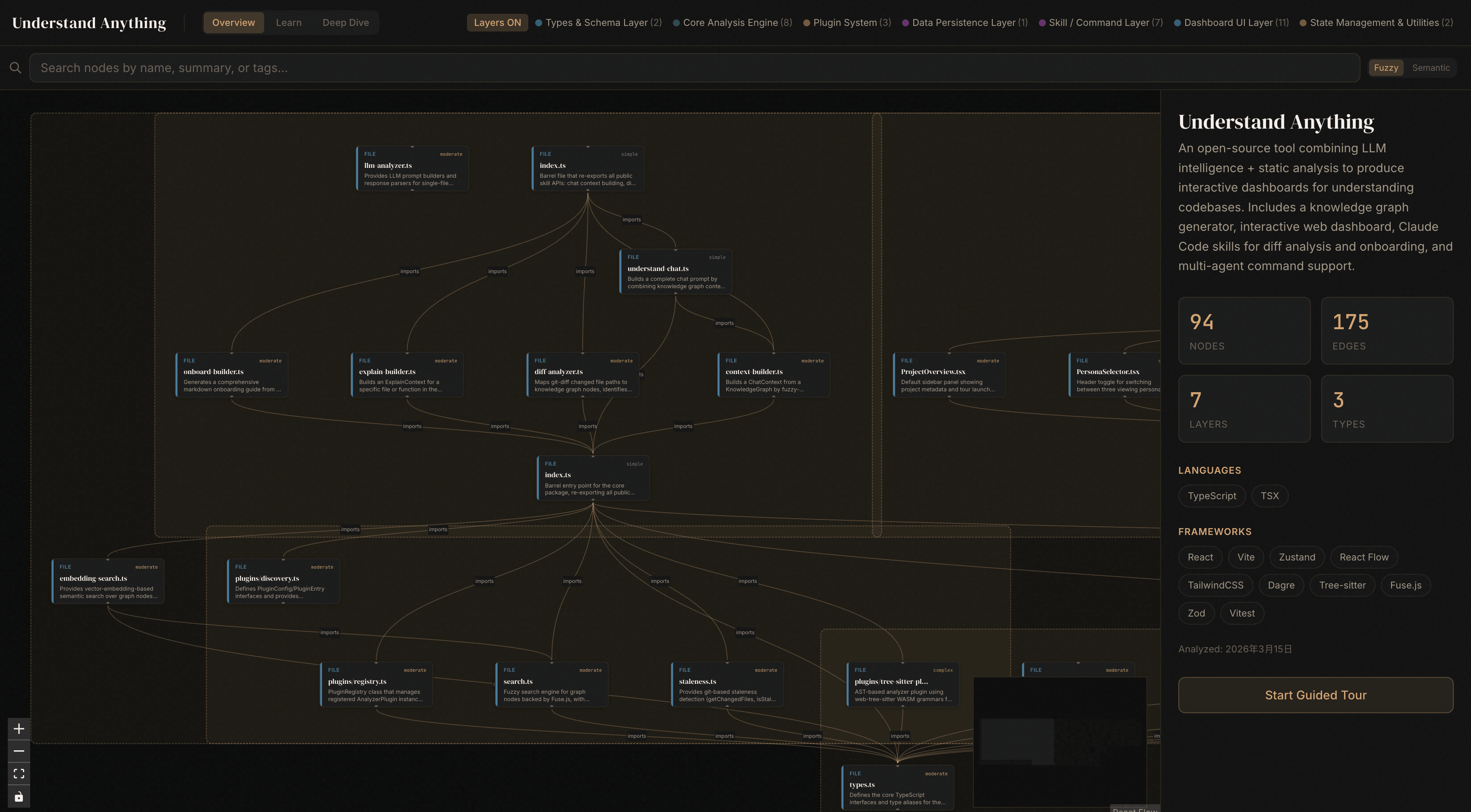
把实际运行效果放进 Pages
这不是示意图。右侧这张图是 Understand Anything 跑完后的真实界面:它先把结构铺出来,再让你去找那些真正该盯的调用链和瓶颈点。Pages 里直接能看到它跑起来的样子。
运行结果
结论很简单
这份 PPT 的主题就是 understand - 可视化&开销分析:先试用,再看它能不能把隐藏调用逻辑和瓶颈可视化,最后只关注重要代码。
能做到的程度
把一个项目拆成能看链路、看归因、看瓶颈的图,而不是只给你一份“长 README 摘要”。
这次的成本
173 files,27,452 lines,1,670,544 bytes,输入约 43-45 万 tokens,输出约 3-5 万 tokens,整轮约 47-50 万 tokens。真正该看的不是 raw content,而是它能不能帮你找到重要代码。
最有价值的输出
单项目调用链定位、跨项目调用链优化、执行次数、执行耗时、瓶颈归因。
下一步
把这页 deck 部署上线,再看它在真实协作里能不能持续产出“重要代码”的定位价值。